
中日韩常用汉字对比分析报告_对比分析流程
总流程如下图所示。以下将逐一说明各环节的作用。
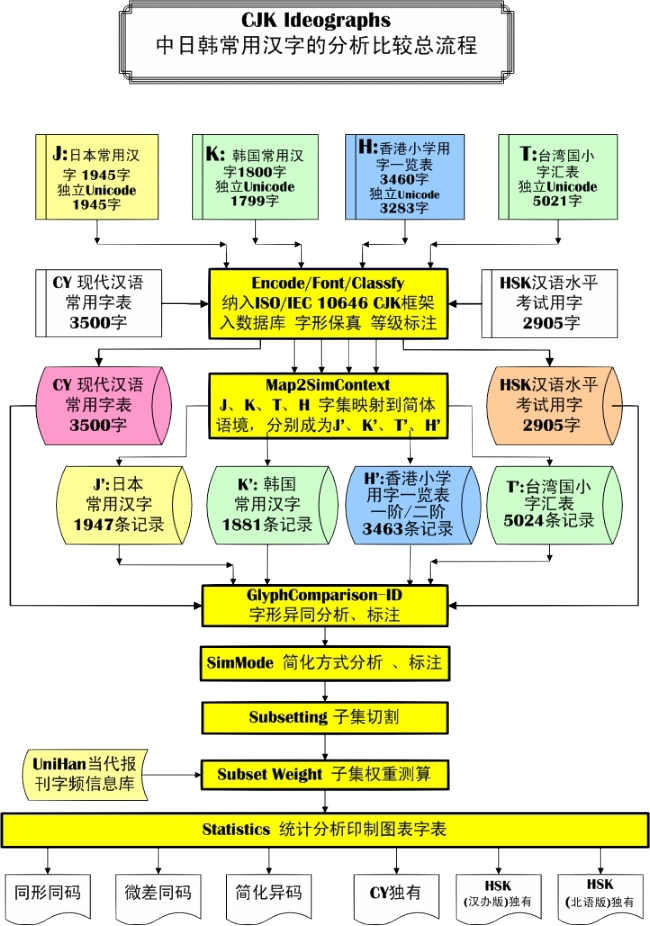
1. Encoding/Fonting/Classify
将各对比对象纳入ISO/IEC 10646 CJK框架,代码转换(如Big5-Unicode, TTE-Unicode,KSC - Unicode)、定码就位、进入数据库。形成J、K、T、H 字集库。在数据库中,记录每个原字表汉字的字形特征,实施“字形保真”和“等级标注”。
- 采用各国家/地区公认标准的字库表征原有汉字;用中国的规范汉字字形(除与韩国对比外皆采用楷体字库)表征映射后的汉字。
- 若该国家/地区的一个字库不能准确显现某汉字的原字形,就借用与其形体最接近的其它字库;
- 如果没有现成的字库能准确表征某汉字的原字形,就用图表示。
- 标注每个汉字在原字表中的等级,如甲/乙/丙/丁,或初中/高中,常用/次常用,一阶/二阶等等。
2. MappingToSimContext
将J、K、T、H 字集映射到简体语境,分别成为J’、K’、T’、H’。
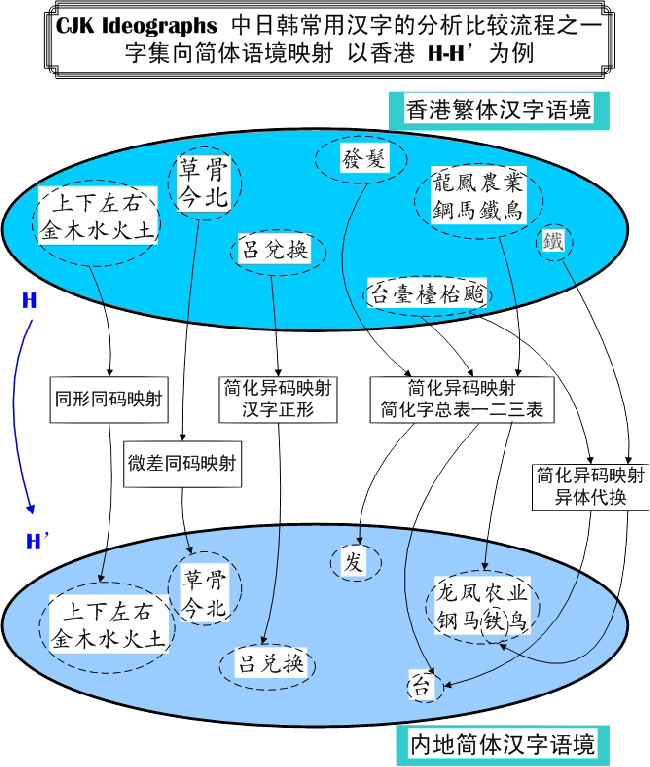
从繁体语境向简体语境的映射,有的是“同码”的映射,有的则是“异码”的映射。对绝大多数映射而言,是一对一的关系;但也有多对一的情形;极少有一对多的关系。因此,映射的总结果,会使镜像字集J’、K’、T’、H’的独立Unicode编码汉字的个数略有减少。(但数据库的映射记录则会由于极个别一对多关系而增加两三条记录数。)
T-T’:映射后,集合字数从5021个收敛到4768个。
H-H’:映射后,集合从3460(字样数)归并到3283个(字数),最终收敛到H’的3098个(已排除重码)。
J-J’:映射后,集合字数从1945个收敛到1920个。
K-K’:映射后,集合字数从1799个(排出重码后)收敛到1779个。
这一道映射程序,是获得诸字集相对可比性的关键,是整个对比分析工作的重要基础。
3. Glyph Comparison-IDentifying
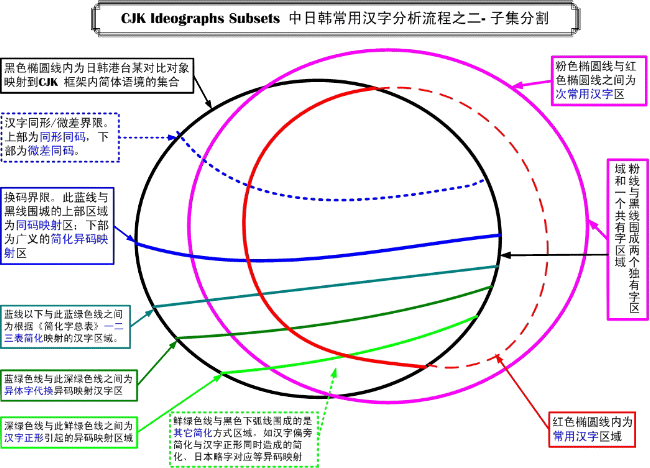
字形异同分析、标注(Glyph-ID)。根据汉字形态的变化,在数据库中逐条标记同形同码、微差同码和简化异码的关系。
- 字形完全相同的,代码不变,标以“同形同码”记号
- 字形有微小差异的,代码亦不变,标以“微差同码”记号[注5]
- 导致转换异码的各种情形,一律标作“简化异码”。
4. SimMode
进一步对“简化异码”进行简化方式分析 、标注其简化模式(SimMode)。实际上,映射过程中的“简化”,是一个广义的概念,它包括下述各种不同的情况:
- 简化:按《简化字总表》 表一、表二、表三简化汉字。
- 异体代换:按《异体字表》代换,这些字可能习惯上被认为是简化汉字。如決-决,異-异。
- 汉字正形[注6]:按《印刷通用汉字字形表》正形造成的、习惯上被认作是简化字。如換-换,爭-争,內-内,別-别。
- 异体简化:既有异体代换,又有简化的变换。如擧-舉-举。
- 条件简化:较明显的一对多简化,有的情况下不能简化。如乾-乾/干,著-著/着。
- 条件异体代换:有条件的异体代换。如珮-佩,珮作人名时就不宜代换为佩。对于矽-硅,槃-盘的条件异体代换,另有说明。
- 正形简化:汉字正形与简化交织在一起。如閱-閲-阅。
- 日文略字对应:日文略字(简化字)对应中国的简化字,如団-团;也可能对应一个传承字,如巣-巢。
- 日文国字对应:日文国字(除略字外,日文独有的汉字)对应一个CJK C-Hanzi G 列下的一个编码汉字,如枠;还有的按字义亦可对应到一个简体字。如闘-斗,働-动。
- 其他:如可简化但尚未编码。
[注] 在图形坐标上,以上分类分别缩写为:简化,条简,正简,异简,异代,条异,正形,日略,国字。
5. Subsetting 子集切割
根据数据库的标注信息,可以将两两对比的字集的并集切割为多个独立的子集。
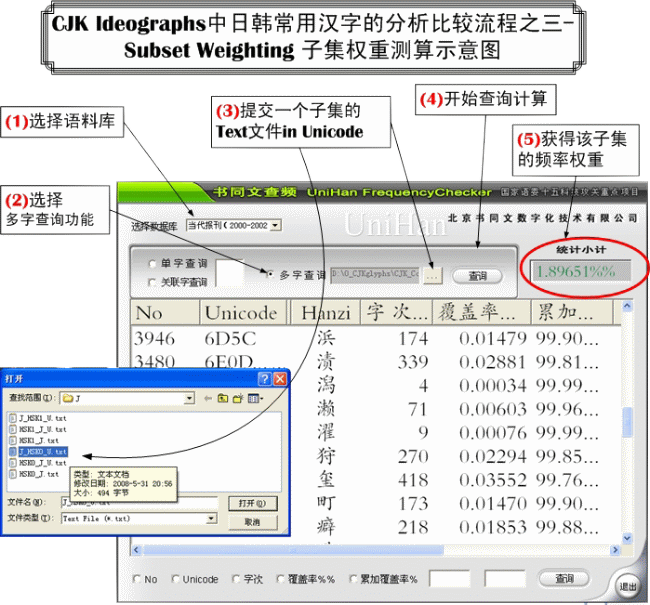
6. Subset Weight 子集权重测算
7. Statistics 统计分析印制图表字表
- 字汇覆盖统计:指每两个国家/地区字表之间共有之字、各自独有之字。
-
字形异同统计:同形同码、微小形差同码、需简化/正形/异体代换-异码之字。这对共有字和独有字都适用。
- 所谓“同形同码”的同形字,主要的是两个字表之间共有字;但是也包括少数或极少数从原字表映射到简体语境的独有字, 他们虽然与CY 和HSK 不相交,但是却落在CJK 之中,如果它与中国的规范字形相同,我们也称其为“同形同码”字。如“壬”是K 独有,CY,HSK 之外,但与中国字形相同,故称“同形同码”字。
- 即使独有字中也含有“简化异码”的情形。如皚-皑,缽-钵,玆-兹和祿-禄都是CY,HSK 之外的字。
- 独有字中,也有极个别的繁体-繁体映射的情况,比如T 中的鮟鱇,映射后T’仍为鮟鱇,这属于可简化、但在CJK 中尚未编码的情形。这与“同形同码”并不矛盾。
- 简化方式统计:简化、异体代换、汉字正形的比例。
- 频率权重测算:计算各子集在现代报刊语料库(含一亿六千万字次的的语料,作为现代汉语语料的一种代表)中的频率权重及其每个单字的平均权重。
- 字表排印:以较大字号字体列出字形对照表,一一示出字形和字码的异同、简化方式,标出其在原字表中的等级。